1 | # -*- coding: utf-8 -*- |
可以识别中文
1 | '''xxx |
多行注释
代码规范
PEP8(Python Enhancement Proposal)
函数和类的定义,代码前后都要用两个空行进行分隔。
在同一个类中,各个方法之间应该用一个空行进行分隔。
二元运算符的左右两侧应该保留一个空格,而且只要一个空格就好。
变量、函数和属性应该使用小写字母来拼写,如果有多个单词就使用下划线进行连接。
类中受保护的实例属性,应该以一个下划线开头。
类中私有的实例属性,应该以两个下划线开头。
类和异常的命名,应该每个单词首字母大写。
模块级别的常量,应该采用全大写字母,如果有多个单词就用下划线进行连接。
类的实例方法,应该把第一个参数命名为self以表示对象自身。
类的类方法,应该把第一个参数命名为cls以表示该类自身。
import语句总是放在文件开头的地方。
引入模块的时候,from math import sqrt比import math更好。
如果有多个import语句,应该将其分为三部分,从上到下分别是Python标准模块、第三方模块和自定义模块,每个部分内部应该按照模块名称的字母表顺序来排列。
不要用检查长度的方式来判断字符串、列表等是否为None或者没有元素,应该用if not x这样的写法来检查它。
采用内联形式的否定词,而不要把否定词放在整个表达式的前面。例如if a is not b就比if not a is b更容易让人理解。
__代替未使用的变量
集合
list
顺序,可重复
查询速度慢,不占内存
添加元素
append()
在末尾添加元素
1 | list.append('chessur') |
insert()
在指定位置添加元素
1 | list.insert(1,'chessur') |
+
1 | list += ['chessur'] |
删除元素
remove()
删除已知的元素,不能删除指定位置的元素
1 | name = ['Andy','York'] |
del
删除元素
1 | list = ['Andy','chessur'] |
删除列表
1 | name = ['Andy','York'] |
清空列表
clear()
1 | list = ['Andy','chessur'] |
比较
Python使用列表的第一个元素进行比较
字符串操作
1 | name = ['Andy'] |
in & not in
1 | name = ['Andy','York'] |
index()
查询参数在列表的位置
1 | name = ['Andy','York'] |
count()
查询同一元素在列表里出现的次数
1 | name = ['Andy','York'] |
reverse()
将列表顺序颠倒
1 | number = [1,2,3,4,5,67,,89,98,3,5,346,56,0] |
会改变原列表
reversed()
返回逆向迭代的序列值
1 | list = [1,2,3,4,5,26] |
不会改变原列表,生成一个新的迭代器对象
[::-1]
1 | number = ['1','2','6'] |
sort()
按顺序排列,改变列表原始值
1 | number = [1,2,3,4,5,67,,89,98,3,5,346,56,0] |
sorted()
按顺序排列,不改变列表原始值
1 | list = ['A','n','d','y'] |
range(0)
range(0)不会迭代
pop()
和集合的pop()不同,列表的pop()默认弹出最后一个元素,并可指定弹出位置
1 | list = [1,2,3] |
dict
顺序,key-value对,key不可重复
查询速度快,占内存
获取value
1 | 变量名[key] 变量名.get(key) 变量名.get(key,'找不到key对应的值时使用的value') |
1 | for key in dict: |
set
无序,不可重复
查询速度快,不占内存
set()
将数据类型转化为集合
1 | list = [1,2,3,3,5] |
add()
1 | set = {1,2,3} |
update()
1 | set = {1,2,3} |
pop()
将第一元素取出,返回该元素
1 | set = {1,2,3} |
集合运算
intersection()
求两集合的交集,等价于 &运算符
1 | set1 = {1,2,3,4,5} |
union()
求两集合的并集,等价于|
1 | set1 = {1,2,3,4,5} |
difference()
求两集合的差集,等价于-
1 | set1 = {1,2,3,4,5} |
symmetric_difference()
求两集合的对称差,等价于^
1 | set1 = {1,2,3,4,5} |
issubset()
判断子集,等价于<=
1 | set1 = {1,2,3,4,5} |
issuperset()
判断超集,等价于>=
1 | set1 = {1,2,3,4,5} |
tuple
不可更改元素
添加元素
1 | tuple = (1,2,3,4,5) |
删除元素
1 | tuple = (1,2,3,4,5) |
求长度
len()
切片
slice[index:length]
第一个索引是0可以省略L[:26]
只用一个:表示从头到尾L[:]
第三个参数,表示每个N个取一个L[::2],每2个元素取一个
索引可以为负值,表示倒数第N个
字符串也是一种list,可以进行切片操作
1 | a = [1,2,3,4,5] |
切片是将值赋给变量
enumerate()
将list加上索引
1 | ['Adam', 'Lisa', 'Bart', 'Paul'] |
zip()
将两个list结合
1 | zip([10, 20, 30], ['A', 'B', 'C']) |
迭代dict的value
values()方法:将dict转换为包含了value的list
itervalues()方法:在迭代过程中依次从dict中取出value,节省内存
同时迭代dict的value和key
items()方法
iteritems()方法
列表生成式
1 | [x * x for x in range(1,11)] |
列表生成式的 for 循环后面还可以加上 if 判断
1 | [x * x for x in range(1, 11) if x % 2 == 0] |
复杂列表生成式
1 | tds = ['<tr><td>%s</td><td>%s</td></tr>' % (name, score) for name, score in d.iteritems()] |
max()
返回集合或参数中的最大值
1 | list = [1,2,3,26] |
min()
返回集合或参数中的最小值
sum()
返回总和
选择分支
if
python3里可以使用下列方式返回函数值
1 | def is_prime(num): |
String
替换
string.replace()
1 | string.replace('被替换','待替换') |
替换多个
1 | string.replace('被替换','待替换').replace('被替换','待替换') |
分割
split()
将字符串分割成列表
1 | split(sep=None, maxsplit=-1) |
input()
python3中没有raw_input()
将raw_input()和input()整合为input()
转换
Ascii码
1 | ord(str) |
字符
1 | chr(num) |
删除
strip()
删除字符串两边的指定字符,默认为空格
1 | string = ' chessur ' |
rstrip()
删除字符串最右边的指定字符,默认为空格
1 | string = ' chessur ' |
lstrip()
删除字符串最左边的指定字符,默认为空格
1 | string = ' chessur ' |
查找
find()
1 | string = 'chessur' |
index()
1 | string = 'chessur' |
index()为找到匹配项时,会报错,报错内容是substring not found
更改字符
capitalize()
首字母大写
1 | string = 'chessur' |
upper()
字符全部大写
1 | string = 'chessur' |
lower()
字符全部小写
1 | string = 'Chessur' |
center()
将字符串以指定的宽度居中,并用指定的字符填充两侧
1 | string = 'chessur' |
ljust()
将字符串以指定的宽度靠左,并用指定的字符填充两侧
1 | string = 'chessur' |
rjust()
将字符串以指定的宽度靠右,并用指定的字符填充两侧
1 | string = 'chessur' |
检查
startswith()
1 | string = 'chessur' |
endswith()
1 | string = 'chessur' |
isdigit()
1 | string = 'chessur' |
isalpha()
1 | string = 'chessur' |
isalnum()
1 | string = 'chessur' |
添加
join()
使用指定字符分割列表中元素,需要元素都是字符类型
1 | list = ['chessur','60','Druid'] |
函数
函数变量优先级
局部作用域>嵌套作用域>全局作用域>内置作用域
1 | def chessur(): |
上面的例子里,变量a是全局作用域,变量b对于函数chessur()来说是局部作用域,对于函数windy()来说是嵌套作用域,内置作用域是Python自带的一些函数。
| 中文名 | 英文名 |
|---|---|
| 局部作用域 | Local |
| 嵌套作用域 | Enclosing |
| 全局作用域 | Global |
| 内置作用域 | Built-in |
可以使用global来让函数中的变量来自全局作用域,使用nonlocal来表示变量来自嵌套作用域
修改后
1 | def chessur(): |
print()
format()
1 | A = 1 |
print(f)
1 | print(f'计算0-9的平方分别为:{result}') |
格式化操作符
| 符号 | 含义 |
|---|---|
| %c | 格式化字符及ASCII |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %o | 格式化无符号八进制 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 用科学计数法格式化浮点数(大写) |
| %g | 根据值的大小决定使用%f或%E |
| %G | 根据值的大小决定使用%f或%E(大写) |
1 | '%c' % 99 |
格式化操作符的辅助命令
| 符号 | 含义 |
|---|---|
| m.n | m是最小总宽度,n是小数点后的位数 |
| - | 结果左对齐 |
| + | 在证书面前显示加号(+) |
| # | 在八进制面前显示‘0o’,在十六进制数面前显示‘0x’,’0X’ |
| 0 | 显示的数字前面填充‘0’代替空格 |
Python的转义字符及含义
| 符号 | 含义 |
|---|---|
| \’ | 单引号 |
| \” | 双引号 |
| \a | 发出系统响铃 |
| \b | 退格符 |
| \n | 换行符 |
| \t | 横向制表符(TAB) |
| \v | 纵向制表符 |
| \r | 回车符 |
| \f | 换页符 |
| \o | 八进制数代表字符 |
| \x | 十六进制数代表字符 |
| \0 | 代表一个空字符 |
| \\ | 反斜杠 |
print()函数默认结尾为\n,可以使用end=' '改变结尾
1 | print('Hello',end=' ') |
在字符串前添加\r,表示将输出的内容返回到第一个指针,可以实现倒计时的功能
1 | import time |
类
方法
类的方法第一个参数是`self
__init__()
用于在创建对象时进行初始化操作
1 | class Druid(object): |
__del__()
在脚本结束时,销毁对象
1 | class Druid(object): |
__str__()
在调用类作为字符串时,使用该方法
1 | class Druid(object): |
__slots__
限定对象可以更改的属性
1 | class Druid(object): |
装饰器
@property
访问器 - getter 方法
@attribute.setter
修改器 - setter 方法
1 | class Druid(object): |
装饰器相当于用一个函数去调用被装饰的函数
静态方法
@staticmethod
静态方法是属于类的方法,而不是对象的方法
类方法
@classmethod
类方法的第一个参数约定名为cls
类之间的关系
is-a
继承或泛化
has-a
关联,关联分为聚合关系和合成关系。聚合关系是整体和部分的关联,如果整体进一步负责了部分的生命周期(整体和部分是不可分割的,同时存在也同时消亡),那么是合成关系
use-a
依赖,类的方法调用了另一个类
继承和多态
一个类从另一个类那里将方法和属性直接继承下来,提供继承信息的称为父类、超类或基类;得到继承信息的称为子类、派生类或衍生类。子类除了继承父类提供的属性和方法,还可以定义自己特有的属性和方法。
super()
可以继承父类的属性
1 | class Feral(Druid): |
继承
1 | class Druid(object): |
多重继承
一个子类可以继承多个父类的属性和方法,相同方法名,以第一个父类为准
多态
子类在继承父类的方法后,可以重写(override)父类的方法,通过方法重写,可以让父类的一个方法在子类中拥有不同的版本。当子类调用重写的方法时,不同的子类对象会表现出不同的行为,这就是多态
抽象类
不能创建对象的类,专门为了让其他类去继承它。Python没有办法直接设置抽象类,可以通过abc模块的ABCMeta元类和abstractmethod装饰器来达到抽象类的效果,如果一个类中存在抽象方法,那么这个类就不能实例化。
正则表达式
re模块
regular expression
1 | import re |
正则表达式前添加r原始字符串,让字符串中的每个字符都是原始的意义。因为正则表达式中有很多元字符和需要进行转义的地方,如果不适用原始字符串就需要将反斜杠写成\\,这样写不仅不方便,也不便于阅读
compile()
编译正则表达式返回正则表达式对象
1 | re.compile(pattern,flags=0) |
使用compile()时,需要把flags提前放在compile()里
match()
用正则表达式匹配字符串,成功返回匹配对象,否则返回None
1 | re.match(pattern,string,flags=0) |
search()
1 | re.search(pattern,string,flags=0) |
search()方法返回第一个匹配的值
形式为
1 | <re.Match object; span=(12, 27), match='密码是:weibomima1,'> |
使用group()获得search()返回的结果
使用group(0)获得search()返回的结果中分组的值
split()
用正则表达式指定的模式分割符拆分字符,返回列表
1 | re.split(pattern,string,maxsplit=0,flags=0) |
sub()
用指定的字符串替换原字符串中与正则表达式匹配的模式,可以用count指定替换的次数
1 | re.sub(pattern,repl,string,count=0,flags=0) |
fullmatch()
match函数的完全匹配(从字符串开头到结尾)版本
1 | re.fullmatch(pattern,string,flags=0) |
findall()
查找字符串所有与正则表达式匹配的模式,返回字符串的列表
1 | re.findall(pattern,string,flags=0) |
re模块包含一个findall()方法它能够以列表形式返回所有满足要求的字符串,若没有匹配到结果,就会返回空列表。flags表示一些特殊功能的标志
finditer()
查找字符串所有与正则表达式匹配的模式,返回一个迭代器
1 | re.finditer(pattern,string,flags=0) |
purge()
清除隐式编译的正则表达式的缓存
re.S
标记:将.的作用扩展到整个字符串,包括\n
re.I
标记:忽略大小写匹配
re.M
标记:多行匹配
文件操作
| mode | 含义 |
|---|---|
'r' |
读取(默认) |
'w' |
写入,会删除之前的内容 |
'x' |
写入,如果文件已存在会产生异常 |
'a' |
追加,将内容写入已有文件的末尾 |
'b' |
二进制模式 |
't' |
文本模式(默认) |
'+' |
更新,既可读又可写 |
打开文件
Python文件操作mode如果想读取,必须为'r'
方法1
1 | file = open ('文件路径','文件操作方式',encoding='utf-8') |
方法2
1 | with open('文件路径','文件操作方式',encoding='utf-8') as file: |
第一种需要手动给关闭文件
第二种需要注意缩进,退出缩进Python就会自动关闭文件
读文件
读取文件可以使用相对路径和绝对路径
相对路径是文本文件相对于现在的工作区而言的路径,并不总是相对于当前正在运行的这个Python文件的路径
Python需要导入os模块来使用~表示家目录
1 | import os |
打开文件
1 | with open('文件路径','r',encoding='utf-8') as file: |
readlines()
读取文件内容,将文件的每一行作为列表元素返回
readlines()会将文件内容取出,如果再次使用read()读取会返回空值
read()
读取文件内容,将所有内容作为字符串返回
readline()
每次读取一行,使用循环读取所有内容
写文件
1 | with open('文件路径','w',encoding='utf-8') as file: |
写文件有2种,w和a
w覆盖掉之前的内容,a是追加内容
write()
直接将一段字符串写入文本
writelines()
writelines(['line0','line1'])
在写文件时,Python不会添加换行符,需要手动添加
操作CSV文件
Python自带处理CSV文件的模块
Python处理CSV文件需要有序字典形式
1 | import csv |
读CSV文件
1 | with open('csvfile','r',encoding='utf-8') as csvfile: |
写CSV文件
1 | with open('csvfile','a',encoding='utf-8') as csvfile: |
模块
random模块
random.randint()
生成整数随机数
1 | random.randint(1,6) |
random.randrange()
可设置步长,默认为1
1 | random.randrange ([start,] stop [,step]) |
random.random()
随机生成0~1之间的浮点数
random.sample()
返回序列(列表、元组、字符串、Unicode字符串、buffer对象、xrange对象)中指定个数的随机切片
1 | list = [x for x in range(1,10)] |
requests模块
requests.get()
1 | requests.get('url') |
返回Response对象
Response.content
返回二进制格式的网页内容
Response.content.decode()
解码为字符格式的网页内容
该方法默认参数为'utf-8',需要根据不同网页进行更改,其他参数有'GBK','GB2312','GB18030'
Response.json()
返回Json格式的Response
requests.status_code
返回响应状态码
内置的状态码查询对象:requests.codes.ok
1 | html = requests.get(url) |
multiprocessing模块
dummy模块
dummy下有一个Pool类,用来实现线程池,线程池下有一个map()方法,可以让线程池里面的所有线程都“同时”执行一个函数
Pool.map()
1 | pool.map(function,iterable) |
第一个参数为函数,第二个参数为可迭代的对象:列表、元组、集合、字典
multiprocessing.Process
创建子进程
1 | import multiprocessing |
启动子进程
multiprocessing.Process.start()
1 | import multiprocessing |
等待子进程结束
multiprocessing.Process.join()
1 | import multiprocessing |
OS模块
创建目录
os.makedirs()
1 | os.makedirs('目录名',exist_ok=True) |
exis_ok=True当存在相同目录名时,不再创建
os.path.join()
1 | os.path.join('目录名',filename+'.后缀名') |
python会根据系统环境(Windows,Linux)添加斜杠
os.listdir()
1 | os.listdir('dir') |
返回列表,列表元素为文件名
os.rename()
1 | os.rename('原文件名','新文件名') |
os.system()
执行系统命令
和subprocess.Popen()的区别:subprocess可以将执行结果通过STDOUT赋给变量
os.getpid()
获取进程号
1 | import os |
lxml模块
XPath语法
1 | info = selector.xpath('//div[@class="useful"]/ul/li/test()') |
直接返回列表,列表中是需要提取的内容
1 | import lxml.html |
获取文本
1 | //标签1[@属性1="属性值1"]/标签2[@属性2="属性值2"]/.../text() |
获取属性值
1 | //标签1[@属性1="属性值1"]/标签2[@属性2="属性值2"]/.../@属性n |
需要使用独特的标签属性值过滤
属性以某些字符串开头
1 | //标签[starts-with(@属性名,"相同的开头部分")] |
json模块
将Python中的对象以JSON格式保存到文件中
json.dump()
将Python对象按照JSON格式序列化到文件中
1 | import json |
json.dumps()
将Python对象处理成JSON格式的字符串
1 | import json |
json.load()
将文件中的JSON数据反序列化称为Python对象
1 | import json |
json.loads()
将字符串的内容反序列化成Python对象
1 | import json |
csv模块
csv.reader()
获取csv文件中的内容,返回csv reader对象
1 | # example.csv |
1 | import csv |
shutil模块
提供了复制文件及文件夹的功能
shutil.copyfile()
复制文件内容到src
1 | shutil.copy(src,dst) |
1 | import shutil |
shutil.copymode()
将src文件权限复制到dst文件,文件内容,所有者和组不受影响
1 | shutil.copymode(src,dst) |
1 | import shutil |
shutil.copystat(src,dst)
将src文件的权限,上次访问时间,上次修改时间以及src的标志复制到dst文件
shutil.copy()
复制文件,权限会一并被复制
1 | shutil.copy(src,dst) |
1 | import shutil |
threading模块
threading.Thread()
创建新的线程
1 | threading.Thread(target = study, args = ('chessur', ),daemon = True) |
target是目标函数,args是目标函数的参数,daemon表示守护进程,主线程退出就不再保留执行
threading.Thread.start()
启动线程
threading.Thread.join()
等待完成
threading.Lock()
创建锁对象
threading.Lock().acquire()
获取锁
threading.Lock().release()
释放锁
tkinter模块
提供图形化界面
tkinter.Tk()
主界面
tkinter.Tk().title()
主界面标题
1 | import tkinter |
tkinter.Tk().geometry()
主界面大小
1 | import tkinter |
tkinter.Tk().wm_attributes()
设置属性
| 参数 | 含义 |
|---|---|
| -topmost | 指定是否是一个永远最前的窗口 |
| -alpha | 指定顶层窗口的透明度。0(完全透明)到1(不透明) |
| -fullscreen | 设置是否占据整个屏幕 |
tkinter.Button()
生成按钮
1 | tkinter.Button(master = None, text = 'Study', command = study) |
tkinter.Button().config()
设置按钮属性
1 | tkinter.Button().config(state = tkinter.NORMAL) |
tkinter.Button().pack()
设置按钮位置
1 | tkinter.Button().pack(side = 'TOP') |
tkiter.messagebox.showinfo()
显示提示信息
1 | import tkinter.messagebox |
异常处理
使用try、except、finally
try写执行的代码except尝试抓捕的异常finally不管有没有异常都会执行的代码
Python标准异常
| 名称 | 描述 |
|---|---|
| BaseException | 所有异类的基类 |
| ZeroDivisionError | 除(或取模)零 |
| IndexError | 序列中没有此索引(Index) |
| ValueError | 传入无效的参数 |
| TypeError | 对类型无效的操作 |
1 | try: |
1 | try: |
进程和线程
进程
进程是操作系统中执行的一个程序,操作系统以进程为单位分配存储空间。
Unix和Linux系统提供了fork()系统调用来创建进程,调用fork()函数的是父进程,创建出的是子进程,子进程是父进程的一个拷贝,但是子进程拥有自己的PID。fork()函数会返回两次,父进程中可以通过fork()函数的返回值得到子进程的PID,而子进程的返回值永远都是0。Python的os模块提供了fork()函数。
Windows系统没有fork()调用,可以使用multiprocessing模块的Process类来创建子进程,该模块还提供了更高级的封装,例如批量启动进程的进程池(Pool)、用于进程间通信的队列(Queue)和管道(Pipe)
可以使用subprocess模块中的类和函数来创建和启动子进程,然后通过管道来和子进程通信。
多进程实例
以做任务为例,单进程做任务就是做完一个任务,再做下一个任务
1 | from random import randint |
多进程做任务
1 | from multiprocessing import Process |
线程
一个进程拥有多个并发的执行线索,简单的说拥有多个可以获得CPU调度的执行单元,这就是所谓的线程。由于线程是在同一个进程下,他们可以共享相同的上下文,因此相对于进程而言,进程间的信息共享和通信更加容易。
使用threading模块来实现多线程
多线程做任务
1 | from threading import Thread |
当多线程共享同一个变量(资源)时,会产生不可控的结果从而导致程序失效甚至崩溃。如果一个资源被多个线程竞争使用,这个资源被称为”临界资源”,”对临界资源”的访问需要加上保护,否则资源会处于”混乱”的状态
使用100个线程向同一个银行账户转账,此时,银行账户余额时一个临界资源,再没有保护的情况下,可能会得到错误的结果
1 | from time import sleep |
执行结果远远小于100元,出现这种情况的原因是,没有对余额这个临界资源加以保护,多个线程同时转账时,会导致一起执行new_balance = self._balance + money,多个线程的账户余额都是初始状态下的0。
这种情况下,可以使用”锁”来保护临界资源,只有获得”锁”的线程可以访问临界资源,其他没有获得”锁”的线程只能被阻塞起来,直到获得”锁”的线程释放了”锁”,其他线程才有机会获得”锁”,这是才可以访问被保护的临界资源
1 | from time import sleep |
Python的多线程并不能发挥CPU的多核特性,这是因为Python的解释器有一个”全局解释器锁”(GIL),任何线程执行前必须先获得GIL,然后没执行100条字节码,解释器就自动释放GIL,让别的线程有机会执行。
协程
单进程单线程异步I/O模型,称为事件驱动模型。
在Python中,单线程+异步I/O的编程称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。
协程最大的优势就是极高的执行效率,因为子程序切换不是线程切换,而是程序自身控制,因此,没有线程切换的开销。
协程的第二个优势就是不需要多线程的锁机制,只有一个线程,不存在同时写变量冲突,在协程中控制共享资源不用加锁,只要判断状态就好了,所以执行效率比多线程高很多。如果想要充分利用CPU的多核特性,最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率。
Python脚本
结构
1 | import <moudle1>,<module2> |
if __name__ == "__main__":
Python模块都包含内置的变量__name__,当运行模块被直接执行时,__name__等于"__main__";如果import到其他模块中,则__name__等于模块名称(不包含后缀.py)。
直接运行
1 | #test.py |
1 | //Output |
作为模块导入
1 | #import_test.py |
1 | //Output |
def __inti__(self,):
在类的方法中,必须有self变量,因为python在调用方法时,会将self作为第一个参数传入方法,若不写self,会出现报错__init__() takes 1 positional argument but 2 were given
dir(object)
以列表形式返回对象属性、方法
1 | #nslookup.py |
sys模块
sys模块可以让Python程序接收参数
1 | #sysExample.py |
socket模块
send()
报错a bytes-like object is required, not 'str'
Python2和Python3在套接字返回值解码上有区别
string类型可以通过encode()方法编码为指定的bytes
bytes类型可以通过decode()方法解码为str,或使用bytes(str,'UTF-8')
1 | socket.send(string) |
将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。
sendall()
1 | socket.sendall(string) |
将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。
内部通过递归调用send,将所有内容发送出去。
sendto()
1 | socket.sendto(string,address) |
将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。该函数主要用于UDP协议。
connect()
连接
1 | socket.socket.connect((host,port)) |
close()
关闭socket
1 | socket.socket.close() |
bind()
将套接字绑定到地址。在AF_INET,以元组(host,port)的形式表示地址。
1 | socket.bind(('host',port)) |
listen()
开始监听传入连接
1 | socket.listen(backlog) |
backlog指定在拒绝连接之前,可以挂起的最大连接数量。
recv()
接收套接字的数据。
1 | socket.recv(bufsize) |
数据以字符串形式返回,bufsize指定最多可以接收的数量。
recvfrom()
1 | socket.recvfrom(bufsize) |
与recv()类似,但返回值是(data,address)
data是包含接收数据的字符串,address是发送数据的套接字地址。
SOCK_STREAM
1.数据流
2.一般是tcp/ip协议的编程
3.有保障的(即能保证数据正确传送到对方)面向连接的SOCKET,多用于资料(如文件)传送
SOCK_DGRAM
1.数据包
2.udp协议网络编程
3.是无保障的面向消息的socket , 主要用于在网络上发广播信息。
AF_INET
IPv4(默认)
AF_INET6
IPv6
AF_UNIX
只能够用于单一的Unix系统进程间通信
异常处理
错误
由于逻辑或语法导致一个程序无法正常执行的问题
异常
程序出错时标识的一种状态
当异常发生时,程序不会再向下执行,而转去调用此函数的地方处理此函数并恢复到正常状态
语法
1 | try: |
1 | #scanport.py |
1 | #udp_server.py |
1 | #udp_client.py |
生成exe文件
1 | pip install pyinstaller |
安装完成之后在Python37/Script文件夹下
1 | pyinstaller -F |
subprocess模块
从python2.4版本开始,可以用subprocess这个模块来产生子进程,并连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值。
subprocess意在替代其他几个老的模块或者函数,比如:os.system os.spawn* os.popen* popen2.* commands.*
subprocess.Popen()
subprocess模块定义了一个类: Popen
1 | class subprocess.Popen( args, |
各项参数含义
| 参数 | 含义 |
|---|---|
| args | 字符串或列表 |
| bufsize | 0 无缓冲 1行缓冲 其他正值缓冲区大小 负值采用默认系统缓冲(一般是全缓冲) |
| executable | 一般不用,args字符串或列表第一项表示程序名 |
| stdin stdout stderr |
None没有任何重定向,继承父进程 PIPE创建管道 文件对象 文件描述符(整数) stderr还可以设置为STDOUT |
| preexec_fn | 钩子函数,再fork和exec之间执行。(Unix) |
| close_fds | Unix下执行新进程前是否关闭0/1/2之外的文件 Windows下不继承还是继承父进程的文件描述符 |
| shell | True Unix下相当于args前面添加了 "/bin/sh" "-c"Windows下相当于添加 "cmd.exe /c" |
| cwd | 设置工作目录 |
| universal_newlines | 各种换行符统一处理为\n |
| startupinfo | Windows下传递给CreateProcess的结构体 |
| creationflags | Windows下,传递CREATE_NEW_CONSOLE创建自己的控制台窗口 |
args:
args参数。可以是一个字符串,可以是一个包含程序参数的列表。要执行的程序一般就是这个列表的第一项,或者是字符串本身。subprocess.Popen(["cat","test.txt"])subprocess.Popen("cat test.txt")
这两个之中,后者将不会工作。因为如果是一个字符串的话,必须是程序的路径才可以。(考虑unix的api函数exec,接受的是字符串
列表)
但是下面的可以工作subprocess.Popen("cat test.txt", shell=True)
这是因为它相当于subprocess.Popen(["/bin/sh", "-c", "cat test.txt"])
在*nix下,当shell=False(默认)时,Popen使用os.execvp()来执行子程序。args一般要是一个【列表】。如果args是个字符串的
话,会被当做是可执行文件的路径,这样就不能传入任何参数了。
1 | #shell.py 攻击者 |
1 | #backdoor.py 受害者 |
shell.py运行
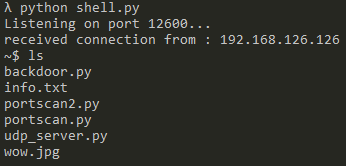
backdoor.py运行

optparse模块
optparse.OptionParser()
1 | parser = optparse.OptionParser(sys.argv[0] + ' ' + '-i <file_with URLs> -r -s [optional]') |
未加参数时回显

optparse.add_option()
1 | parser.add_option('-i',dest='domains',type='string',help='specify target file with URLs') |
--help显示参数

optparse.parse_args()
1 | (options,args) = parser.parse_args() |
返回两个值,options包含所有options的对象,参数作为对象的属性,args解析options后剩余参数的列表
1 | domains = options.domains |
optparse.attributes
option.action
默认为store
option.type
默认为string
option.dest
告诉optparse将参数写在哪里
option.help
help选项显示内容
1 | #fake_dirbuster.py |
cymruwhois模块
Client()
1 | from cymruwhois import Client |
Clien().lookupmany_dict()
1 | #返回字典,索引为ip |
1 | #whois.py |
执行系统命令
os.system()
1 | import os |
subprocess.Popen()
1 | import subprocess |
winreg模块
_winreg模块在Python3中被重命名为winreg
winreg.OpenKey()
打开特定key
1 | winreg.OpenKey(key,sub_key[,res=0[,sam=KEY_READ]]) |
返回一个句柄对象key是一个已经打开的键,或任意一个预定义的HKEY_*常量sub_key是一个字符串,表示要打开的子键res为保留整数,必须为0,默认为0sam是一个整数,指定访问掩码,描述密钥的所需安全访问策略
修改键值
1 | winreg.SetValueEx(key, value_name, reserved, type, value) |
key是一个已经打开的键,或任意一个预定义的HKEY_*常量value_name是一个字符串,命名了哪一个值与之关联reserved可以使用任何值,0表示总是被传递给APItype是一个整数,描述了数据类型。具体类型参考:Registry Value Typesvalue表示被赋予的新值
1 | import sys,base64,os,socket,subprocess |
参考
[1] Python黑客学习笔记:从HelloWorld到编写PoC(上)
[2] Python黑客学习笔记:从HelloWorld到编写PoC(中)
[3] Python Tutorials